图论

图论
Zyx_2012首
图论,是 OI 中一个非常重要的分类,涵盖多种算法、题型
包括但不限于
图的存储
DFS (图论)
BFS (图论)
树上问题
有向无环图拓扑排序
最短路问题
生成树问题
斯坦纳树
拆点
连通性相关
环计数问题
最小环
2-SAT
欧拉图
哈密顿图
二分图
平面图
弦图
图的着色
网络流
图的匹配
Prüfer 序列
矩阵树定理
LGV 引理
最大团搜索算法
支配树
……
但是,这篇文章提到的,也是 CSP - S 复赛中涵盖的考点,只有
- 最小生成树
- 最短路
- 拓扑排序
- 最近公共祖先
其中,最短路问题可以通过最小生成树改写,就不过多赘述了。
最小生成树
我们定义无向连通图的 最小生成树(Minimum Spanning Tree,MST)为边权和最小的生成树。
注意:只有连通图才有生成树,而对于非连通图,只存在生成森林。
我们这里主要说 Prim 算法
Prim 算法
Prim 算法的基本思想是从一个结点开始,不断加点(而不是 Kruskal 算法的加边)。
具体做法
算法步骤及总结
初始化
输入图的顶点数 n 和边数 m。
使用 邻接表 adj 存储图的边,adj [i] 存储从顶点 i 出发的所有边(以对 (v, w) 形式存储,其中 v 是邻接点,w 是边的权重)。
- 数据结构定义
d 数组:用来存储从起点到每个节点的最短距离,初始化为 INF(表示不可达)。
vis 数组:标记每个节点是否已经访问过,防止重复访问。
pq(优先队列):一个最小堆,用来选择当前距离最小的节点。
res:最小生成树的总权重。
cnt:最小生成树包含的边数。
- 输入边信息
使用 cin 输入每一条边的信息:端点 u 和 v,边的权值 w。
由于是无向图,我们将边的两端都存储在邻接表中:adj [u].push_back ({v, w}) 和 adj [v].push_back ({u, w})。
- Dijkstra 风格的 Prim 算法过程
起点设为节点 1,将其最短距离 d [1] 初始化为 0,并将其加入优先队列 pq。
每次从队列中取出一个距离最小的节点 u,并进行以下操作:
如果节点 u 已经被访问过,跳过。
标记 u 为已访问。
将 u 的最短距离加入最小生成树的总权值 res,并增加边数 cnt。
遍历所有与 u 相连的边 (u, v),如果节点 v 没有被访问且通过 u 到 v 的距离更短,则更新 d [v],并将新更新的距离 w 和节点 v 推入队列 pq。
- 判断图的连通性
如果最小生成树包含的边数 cnt 等于 n - 1,说明图是连通的,输出最小生成树的总权值 res。
否则,图不连通,输出 “orz”。
- 代码总结
Prim 算法通过每次选择当前距离最小的节点,不断更新周围节点的最短路径,最终生成一个最小生成树。由于使用了优先队列,时间复杂度为 O ((n + m) log n),适用于稠密图和稀疏图。
题目及分析
也是一道非常简单的题目
P3366 【模板】最小生成树
题目描述
如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出
orz。输入格式
第一行包含两个整数 $N,M$,表示该图共有 $N$ 个结点和 $M$ 条无向边。
接下来 $M$ 行每行包含三个整数 $X_i,Y_i,Z_i$,表示有一条长度为 $Z_i$ 的无向边连接结点 $X_i,Y_i$。
输出格式
如果该图连通,则输出一个整数表示最小生成树的各边的长度之和。如果该图不连通则输出
orz。输入输出样例 #1
输入 #1
2
3
4
5
6
1 2 2
1 3 2
1 4 3
2 3 4
3 4 3输出 #1
说明 / 提示
数据规模:
对于 $20%$ 的数据,$N\le 5$,$M\le 20$。
对于 $40%$ 的数据,$N\le 50$,$M\le 2500$。
对于 $70%$ 的数据,$N\le 500$,$M\le 10^4$。
对于 $100%$ 的数据:$1\le N\le 5000$,$1\le M\le 2\times 10^5$,$1\le Z_i \le 10^4$,$1\le X_i,Y_i\le N$。
样例解释:

所以最小生成树的总边权为 $2 + 2+3 = 7$。
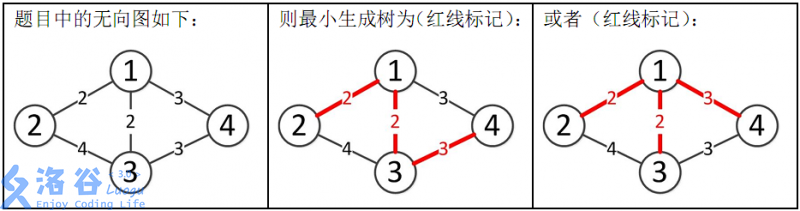
思路及解法
模板题,思路刚才讲过了,直接看代码
1 |
|
最短路径
最短路是图论里最常见也最实用的一类问题:给定起点(有时还有终点),在图上找一条代价(权重、时间、距离)最小的路径。CSP - S 和很多比赛会经常考到这类题。下面按风格把两种常用算法写清:Dijkstra(单源非负权最短路)和 A*(启发式寻路,适合单对点、能用启发函数加速的场景)。
术语说明:
adj用邻接表,边用(v, w)表示,变量习惯u, v, w。
代码风格偏竞赛模板(万能头、using namespace std、i++循环等)。
Dijkstra 算法(单源最短路,非负权)
思路
从起点出发,每次 “松弛” 当前距离最小的未确定点,直到处理完所有点 —— 优先队列是关键。
适用条件
- 图为稀疏或中等稠密(
m较大时也能用,但复杂度显现); - 边权 非负(否则需要 Bellman-Ford、SPFA 或特殊处理)。
复杂度
使用二叉堆 / 优先队列:O((n + m) log n)(常写作 O(m log n))。
代码模板
1 |
|
常见陷阱 / 优化
- 别忘了边权非负的前提;有负权边要用 Bellman-Ford 或 Johnson。
- 对于稠密图(
m ≈ n^2)用O(n^2)的数组实现(不带堆)可能更快。 - 如果只需要到某个单一目标的最短路,可以在弹出目标节点时提前退出(小优化)。
A* 算法(启发式单源 - 单目标最短路)
思路
在 Dijkstra 的基础上加入启发估价 h(x)(从 x 到终点的估计代价),优先扩展 f(x)=g(x)+h(x)(g 为从起点到 x 的实际代价)。如果 h 是 ** 可接受(admissible)* 的(永远不高估真实代价),A 能保证找到最短路径,并且通常比 Dijkstra 扩展更少的结点。
适用条件
- 适合找 单源到单目标 的最短路(如地图寻路、网格题、点对最优路径)。
- 需要能设计一个快速计算且可接受的启发函数
h(x)(例如欧氏距离、曼哈顿距离等)。 - 在最坏情况下(
h(x)=0)退化为 Dijkstra。
复杂度
理论上依赖于 h 的好坏。若 h 很弱,复杂度接近 Dijkstra;若 h 很强(接近真实距离),扩展结点可以大幅减少。一般无法给出严格的多项式界定(依启发函数而定)。
何为 “可接受(admissible)”?
h(x) 对任意结点 x,都不能超过从 x 到目标的实际最短代价(即低估或等于真实代价)。这保证了 A* 的最优性。
代码模板(网格 / 通用图形式 - C++)
下面是一个通用模板(把启发函数留作可替换部分)。模板里假设节点用整数标识,且能从 heuristic(u, goal) 获得估价。
1 |
|
在网格上的 A*(启发函数示例)
- 曼哈顿距离(4 - 连通格子):
h = |x1 - x2| + |y1 - y2| - 欧氏距离(取整):适用于允许斜向移动且代价与距离成正比的情况
- Chebyshev 距离:适用于 8 - 连通且斜向与直向代价一样的情况
记住:必须保证 h 不会高估真实最短路,否则可能得到非最优解。
实战建议 / 调参
- 如果题目是普通图且要从一个起点求到所有点的距离,用 Dijkstra。A* 主要用于 “有明确目标且能写出好启发函数” 的场景。
- 在稀疏且目标明确的情形下,A* 往往比 Dijkstra 快,因为它把搜索 “引导” 向目标,省掉很多无关分支。
- 若启发函数计算开销大,需权衡:
h省掉的扩展结点是否能抵消计算h的成本。 - 对于复杂几何图或带障碍的地图,常把
h做得略保守但高效(例如预处理一些近似距离表)。










